
Czy model językowy chińskiego DeepSeek, który doprowadził na początku tego tygodnia do silnych przecen spółek związanych ze sztuczną inteligencją, tak naprawdę okaże się tym, czym była taśma montażowa dla rozwoju motoryzacji? Pewności nie ma, ale tak może być – Chińczycy pokazali światu, że modele AI nie muszą być drogie ani w budowaniu, ani w używaniu. Co to oznacza dla spółek rozwijających AI? Kto na tym wygra, a kto przegra? Sprawdzam
Cofnijmy się o ponad stulecie w czasie. Mamy rok 1913, jest pięć lat po uruchomieniu produkcji Forda T. W fabryce Forda w Highland Park uruchamiana jest taśma montażowa, pierwsza w świecie motoryzacji. Wydajność robotników – choć niekoniecznie satysfakcja z pracy – wspina się na nowe wyżyny, złożenie jednego samochodu trwa tylko 93 minuty, a jego cena, w przeliczeniu na dolary z 2023 r., spada z 25 506 dolarów w roku 1910 do 5 156 dolarów w 1924. Prawie pięciokrotnie.
- Zdalny leasing, czyli auto dla firmy bez wychodzenia z domu? Coraz więcej banków wprowadza tę nowinkę. Jak to działa? [POWERED BY BNP PARIBAS]
- Jedziesz samochodem na weekend? Zanim wrzucisz walizki do bagażnika, sprawdź warunki ubezpieczenia auta. Na wszelki wypadek [POWRED BY PZU]
- PZU zaprasza posiadaczy oszczędności do tańca. Na parkiecie nowy ETF: daje udział w sukcesach 1300 największych spółek świata. Czy to będzie hit? [POWERED BY PZU]
Dzięki pomysłowi na zwiększenie efektywności produkcji samochód przestał być produktem luksusowym. Stał się dostępny dla szerokich mas bogacącej się amerykańskiej klasy średniej. Ford T zmotoryzował Amerykę i na długo stał się najlepiej sprzedającym się samochodem na świecie. Dopiero w 1972 roku wyprzedził go równie legendarny ‘garbus’ Volkswagena.
Nasza droga AI. Droga, więc elitarna
To teraz przenieśmy się z powrotem do lat 20. naszego wieku. Jest rok 2022, startup OpenAI postanawia pochwalić się umiejętnościami swojej sztucznej inteligencji, a konkretnie modelu GPT. W ostatnim dniu listopada firma udostępnia ChatGPT – chatbota opartego na modelu GPT. Wieści o nowych możliwościach sztucznej inteligencji okrążają świat w zawrotnym tempie.
Wielkie firmy technologiczne, takie jak Microsoft, Google, Amazon czy Meta zaczynają inwestować olbrzymie pieniądze w AI. Microsoft inwestuje około 13 mld dolarów w OpenAI, Google wkłada olbrzymie pieniądze w stworzenie własnych modeli, ale i tak dorzuca parę miliardów konkurencyjnemu dla OpenAI startupowi Anthropic, w który inwestuje również, także na poziomie miliardów dolarów, Amazon. Meta rozwija własną AI z pomocą jednego z najbardziej znanych naukowców w tej dziedzinie, Yanna LeCuna. Dodatkowo wydaje dziesiątki miliardów na centra danych, mimo że w odróżnienia od Microsoftu, Google czy Amazona nie oferuje usług chmurowych.
Jedno, co się w tej historii powtarza, to miliardy, czasem wręcz dziesiątki miliardów dolarów. Jak się okazuje, nowa AI, którą nazwano generatywną sztuczną inteligencją (GenAI), jest bardzo droga. Droga w zbudowaniu i droga w stosowaniu. Oczywiście efekty skali swoje zrobiły – GenAI jest dziś dużo tańsza niż dwa lata temu.
I kiedy mówię droga, to mam na myśli koszt dla firm, które oferują ją klientom. Największe modele GenAI są olbrzymie i zużywają olbrzymie ilości mocy obliczeniowych. To oznacza olbrzymie inwestycje w sprzęt komputerowy, ale również olbrzymie rachunki za prąd. Tylko w 2025 r. tylko jedna firma, Meta, odda do użytku moce obliczeniowe o mocy (czytaj – zużyciu) 1 GW. Tyle ile w godzinach szczytu zużywało w styczniu przeszło 1 mln Polaków.
Ten problem z kosztami w dużym stopniu pogłębiają najnowsze trendy w AI. W ciągu ostatniego mniej więcej pół roku okazało się, że dotychczasowy kierunek rozwoju GenAI – coraz większe modele zasilane coraz większymi zestawami danych – przestaje dawać oczekiwane rezultaty. Firmy z branży AI zaczęły rozwijać więc tak zwane modele „rozumujące” – takie, które nie „wypluwają” pierwszej rzeczy, jaką im (wirtualna) ślina na język przyniesie (bo tak generalnie działają obecnie najpowszechniejsze duże modele językowe, takie jak GPT-4o, Gemini czy Llama), a zamiast tego w kolejnych iteracjach rozważają odpowiedź.
Modele te, takie jak o1 od OpenAI, czy Gemini Flash Thinking od Google’a w trudniejszych zastosowaniach – takich jak zaawansowana matematyka, nauki ścisłe czy programowanie – mają zastąpić modele tradycyjne. Szybko się jednak okazało, że modele te, oprócz oczywistych zalet, mają jedną podstawową wadę – wykładniczo rosnące koszty. Najlepszy z tych modeli na jedną odpowiedź potrzebował mocy obliczeniowych kosztujących przeszło 1000 dolarów. Za drogo do zdecydowanej większości zastosowań.
DeepSeek jak taśma montażowa dla AI?
A teraz w naszej historii w końcu pojawia się DeepSeek – laboratorium AI będące przybudówką funduszu hedgingowego High-Flyer, specjalizującego się w handlu algorytmicznym. Istniejące od 2023 r., ale dopiero niedawno wieści o nim zatoczyły szersze kręgi.
W grudniu zeszłego roku DeepSeek opublikował model V3. Model przeszedł w dużej mierze niezauważony przez media, mimo że miał kilka interesujących cech: każdy mógł go sobie ściągnąć na własną infrastrukturę całkowicie za darmo, dodatkowo w standardowych testach był lepszy od większości istniejących modeli i porównywalny z czołowymi obecnie modelami GPT-4o od Open AI i Claude Sonnet 3.5 od firmy Anthropic.
Ponadto, według twierdzeń chińskiej firmy wytrenowanie modelu kosztowało raptem niecałe 6 mln dolarów. W połowie zeszłego roku szef Anthropica szacował, że wytrenowanie jego modelu kosztowało wówczas 100 mln dolarów,a a kolejne modele mogą kosztować 1 mld dolarów. DeepSeekowi udało się to za cenę dwa rzędy wielkości niższą.
Model jest efektywny nie tylko na etapie trenowania, ale również na etapie korzystania z niego – dostęp programistyczny przez tak zwane API będzie kosztować około 1/9 tego, co OpenAI życzy sobie za dostęp do GPT-4o. Będzie, bo w okresie do 8 lutego ceny będą promocyjne, a więc jeszcze niższe.
Ale moment olśnienia przyszedł jeszcze później, bo 20 stycznia. Tego dnia DeepSeek ogłosił i udostępnił dla wszystkich model R1, a więc konkurenta dla wspomnianego wyżej „rozumującego” modelu o1 od OpenAI. Modelu, za dostęp do którego spółka Sama Altmana życzy sobie 200 dolarów miesięcznie. Jeśli postanowimy skorzystać z R1 na infrastrukturze DeepSeeka, to będzie nas to kosztować raptem 1/30 tego, co za dostęp do o1.
Dostaliśmy więc technologię, która obniża koszt tworzenia AI i dostarczania jej klientom co najmniej 10-krotnie. Przypomnijmy – taśma montażowa obniżyła cenę Forda T około 5-krotnie i dzięki temu przyczynił się do boomu motoryzacyjnego w USA. Teraz podobną rolę mogą odegrać modele DeepSeek i zastosowane w nich technologie. AI stanie się powszechnie dostępna. Bo technologie wykorzystywane w DeepSeek chińska firma opisała w artykułach naukowych i są dostępne dla wszystkich.
Kto na tym straci? Długa lista przegranych
Pierwszą, dość oczywistą ofiarą DeepSeeka będą te startupy, które już wpompowały miliony, a czasem wręcz setki milionów dolarów w zbudowanie własnych modeli AI. Istnieje spore ryzyko, że firmy takie jak OpenAI, Anthropic czy Cohere niedługo będą musiały konkurować z wieloma o wiele tańszymi ofertami usług dostępu do modeli. Nawet jeśli infrastruktura DeepSeeka nie wytrzyma napływu nowych użytkowników, to amerykańskie firmy z infrastrukturą chmurową na pewno udostępnią chiński model i to za ułamek ceny narzucanej dziś przez największe firmy AI. Już teraz udostępnienie go zapowiedziała Nvidia.
Ta tańsza konkurencja dla istniejących modeli AI zapewne wymusi obniżki cen i przyspieszoną amortyzację inwestycji w takie modele w księgach rachunkowych ich twórców. Już dziś startupy te nie są zbyt dochodowe, a odpisy wartości modeli AI mogą ich straty pogłębić.
Jest w tym wszystkim pewien aspekt optymistyczny dla OpenAI i jego obecnych konkurentów – przyszłe koszty zarówno trenowania modeli jak i korzystania z nich będą dużo niższe. Bo oczywiście wbudują one technologię DeepSeek w swoje przyszłe modele. Tyle tylko, że koszty będą niższe dla wszystkich – bariery wejścia na rynek AI znacząco się obniżą, a konkurencja zapewne stanie się ostrzejsza.
Pojawieniem się DeepSeeka nie są więc zachwycone fundusze, które zainwestowały w startupy budujące modele AI. Josh Kushner z Thrive Capital narzekał, że chiński model został stworzony z treści generowanych przez czołowe amerykańskie modele a Philippe Laffont, założyciel firmy private equity Coatue kwestionował czy modele AI powinny w ogóle mieć prawo być otwartoźródłowe. Z kolei OpenAI bada czy przypadkiem Chińczycy nie wykorzystali nielegalnie treści z OpenAI, by wytrenować swój model. Można tu mówić o pewnej hipokryzji – OpenAI sam był wielokrotnie oskarżany o korzystanie z treści należących do innych firm i osób bez zezwolenia.
Kolejnym stratnym na pewno będzie Nvidia i jej konkurenci, czyli firmy oferujące karty GPU wykorzystywane przy budowaniu modeli. Przy gwałtownym spadku zapotrzebowania na moce obliczeniowe ze strony modeli AI, popyt na produkty Nvidii zapewne spadnie. Niekoniecznie będzie to widać w następnych paru miesiącach – portfel zamówień firmy był dotychczas bardzo głęboki.
Ale zapewne niedługo dostawcy usług chmurowych zaczną rewidować plany inwestycyjne, ciągnąc w dół popyt, sprzedaż i marże. Perspektywy dla firmy, przynajmniej w średnim terminie, zapewne istotnie się pogorszą, ciążąc na jej mocno wyśrubowanej wycenie. Nic dziwnego, że kurs firmy spadł z okolic 150 dolarów do nieco ponad 120 dolarów.
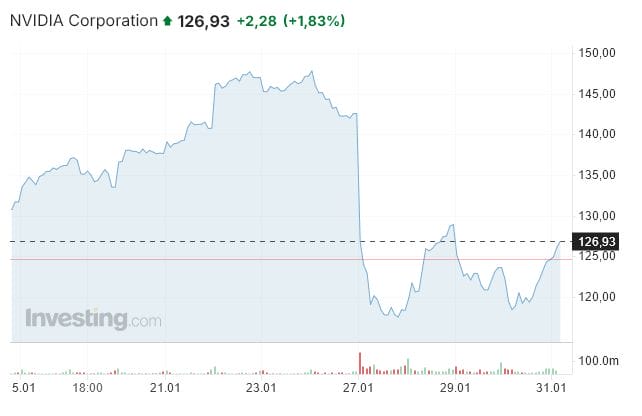
Sukces DeepSeeka ciążył – z tych samych powodów – wycenie AMD, czy Broadcoma. Również dostawcy spółek chipowych, tacy jak TSMC czy ASML, tracili na rynku akcji. Perspektywy tych spółek, przynajmniej średnioterminowo, wyglądają gorzej, niż można było zakładać jeszcze miesiąc temu.
Nieco bardziej zniuansowana jest sytuacja dostawców rozwiązań chmurowych – firm takich jak Amazon, Microsoft czy Google. Firmy te zainwestowały miliardy w startupy AI – zwłaszcza OpenAI i Anthropic i być może będą musiały część tych inwestycji spisać na straty. Na potęgę kupowały również po wysokich cenach karty od Nvidii – a te ceny mogą niedługo zacząć spadać.
Dodatkowo, jeśli zasobożerność nowych modeli AI opartych na technologii DeepSeek będzie dużo niższa niż obecnych modeli, to popyt na moce obliczeniowe może chwilowo spaść – a wraz z nim przychody dostawców chmury. Z drugiej strony, firmy te będą zapewne mogły, przynajmniej tymczasowo, nieco obniżyć wydatki inwestycyjne, a to inwestorzy zapewne docenią.
Jednak, jeśli boom na tanie rozwiązania AI faktycznie nadejdzie, to firmy chmurowe będą pierwszymi, które na tym skorzystają. Bo to one dostarczają infrastrukturę dla AI. Tak samo jak rozwój motoryzacji przyczynił się do rozwoju przemysłu naftowego w USA, tak powszechne wykorzystanie AI zapewni stały napływ biznesu dla Amazona, Microsoftu i Google. Nic więc dziwnego, że na wieść o DeepSeeku, kursy akcji Microsoftu czy Amazona nie zareagowały zbyt nerwowo, a niewielkie straty zostały szybko odrobione.
Dość szczególnym przypadkiem jest Meta. Firma dopiero co ogłosiła, że w infrastrukturę do AI zainwestuje w tym roku 60-65 mld dolarów. Jeśli nie zrewiduje tych planów, to może się okazać, że infrastruktury tej jest o wiele za dużo na jej potrzeby – jej szef Mark Zuckerberg już ogłosił, że technologia DeepSeek zostanie wbudowana w modele firmy. A trzeba pamiętać, że Meta nie jest firmą sprzedającą dostęp do chmury – infrastrukturę buduje na swoje potrzeby. Czy nie pojawi się przypadkiem nowy gracz chmurowy?
Kogo ozłoci Deepseek?
Na tym wszystkim zyskamy przede wszystkim my – potencjalni użytkownicy AI. Technologia DeepSeek może sprawić, że usługi będą powszechnie dostępne i tanie.
Po drugie, skorzystają – już teraz – firmy oferujące rozwiązania AI oparte na modelach innych firm. Przesiadka na tańsze modele, takie jak DeepSeek, niewątpliwie obniży im koszty. Co prawda chińska firma zapowiada, że podniesie ceny od 8 lutego, ale i tak model V3 będzie około 9x tańszy niż GPT-4o od OpenAI. Dziewięciokrotna obniżka kosztów to w biznesie rzadkie szczęście.
Skorzystają również te startupy, które planowały zbudować soje modele AI, ale dotąd nie było ich stać. DeepSeek pokazał, że nawet bardzo duży model – DeepSeek V3 ma ponad 600 mld parametrów – można zbudować za kilka milionów dolarów. A to już nie jest kwota nie do udźwignięcia dla firmy ze wsparciem inwestorów VC.
I, przynajmniej na razie, zyska środowisko. Mniejsze zużycie mocy obliczeniowych to mniej CO2 lecącego do atmosfery. Jak to będzie wyglądać w dłuższym terminie, zobaczymy.
Zobacz też nasze wideofelietony i wideorozmowy:
zdjęcie tytułowe: Pixabay
![Chiński „złoty” zamach. Hongkong idzie na wojnę z zachodnimi giełdami. Co to może oznaczać dla cen złota? [KOMENTARZ GOLDSAVER]](https://subiektywnieofinansach.pl/wp-content/uploads/2026/06/hongkong-idzie-po-zachodnie-zloto-640x400.jpg)



